Der Blick unter die Haube
Bevor wir die Inhalte aus dem Netz auf unseren Rechner ziehen können, müssen wir uns zunächst damit beschäftigen, wie die Websiten aufgebaut sind, die diese Inhalte zur Verfügung stellen. Es ist ganz einfach in modernen Browsern, sich den Quellcode einer Website anzeigen zu lassen, auf der man sich gerade befindet. Inzwischen ist es nämlich Standard, dass überall die Taste F12 ein zweites Fenster zu dessen Anzeige öffnet. Im zu Windows 10 gehörigen Browser Edge teilt sich das Browserfenster in zwei übereinander geordnete Teile, so dass wir unterhalb der Parzival-Ausgabe der bibliotheca augustana folgenden Code angezeigt bekommen:
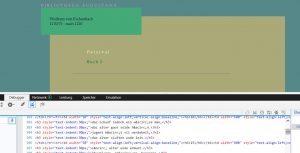
Betrachten wir uns diesen Text etwas genauer!
Die Zeile 202 lautet beispielsweise:
<h3 style="text-indent:30px;">daz schuof iedoch ein wîse man,</h3>
So schwer ist es nicht, den mittelhochdeutschen Text in dieser Zeile auszumachen, auch wenn uns möglicherweise die Buchstabenfolge wîse ein wenig verwirrt. Bei dieser Verszeile wird der Text in <h3>-tags geklammert und offensichtlich wird der Absatz mit einem Einzug von 30 Pixel (text-indent:30px) vom rechten Rand positioniert. Wenn wir im oberen Fenster ein wenig hin und her scrollen, finden wir schnell die vom Browser generierten Ansicht des HTML-Codes dieser Zeile (V. 5.11) und können versuchen, durch den Vergleich beider Fensterinhalte zu einem besseren Verständnis des Codes zu gelangen. So finden wir auf diese Weise unter anderem heraus, dass die Buchstabenfolge &icir; dazu dient, die Graphie |î| wiederzugeben, die das lange mittelhochdeutsche i beschreibt.
Wir werden uns gleich eingehender mit dem Quelltext beschäftigen, aber zuvor wollen wir uns von diesem eine lokale Kopie auf unserem eigenen Rechner beschaffen und setzen dazu erstmals die Programmiersprache Python ein. Unser kleines Skript enthält nur 6 Zeilen Programmiercode:
import urllib.request
import html
FileName = "https://www.hs-augsburg.de/~harsch/germanica/Chronologie/13Jh/Wolfram/wol_pa01.html"
fInput= urllib.request.urlopen(FileName)
for l in fInput:
print(html.unescape(l.decode('utf-8')))
Von einem so kurzen Programm können wir kaum etwas Spektakuläreres erwarten, als das, was es tatsächlich tut: Es übernimmt aus der Variablen Filenname eine URL und gibt uns den Quelltext der durch die URL angegebenen Website in das Ausgabefenster der Python-Entwicklungsumgebung aus. Den Inhalt von Filename, die URL, haben wir direkt per copy&paste aus der Kopfzeile unseres Browsers übernommen und deshalb wundert es uns auch nicht, dass im Konsolenfenster erwartungsgemäß derselbe Text durchscrollt, den wir auch beim Betätigen der Taste F12 über der Website in unserem Browserfenster angezeigt bekommen haben. Oder doch beinahe derselbe Text … Doch darauf werden wir gleich eingehen. Zuvor ergänzen wir den Code noch um drei weitere Textzeilen:
import urllib.request
import html
FileName = "https://www.hs-augsburg.de/~harsch/germanica/Chronologie/13Jh/Wolfram/wol_pa01.html"
fInput= urllib.request.urlopen(FileName)
fOutput = open("D:/ParzivalLachmann.html",mode='w',encoding='UTF-8')
for l in fInput:
print(html.unescape(l.decode('utf-8')))
fOutput.write(html.unescape(l.decode('utf-8')))
fOutput.close()
Jetzt wird uns der von der Website heruntergeladene Quelltext nicht nur im Konsolenfenster der Entwicklungsumgebung angezeigt, sondern auch, Zeile für Zeile in eine Textdatei geschrieben. Da wir dieser Textdatei die Dateiendung .html gegeben haben, lässt sich diese Datei jetzt in einem Texteditor öffnen und betrachten und wenn wir es wollen auch auf Papier ausdrucken. Wir können uns die Datei aber auch in unserem Browser anzeigen lassen, wenn wir sie auf die für unser Betriebssystem übliche Art „öffnen“. Dann wird uns wieder im Beispielbrowser Edge von Windows 10 ungefähr diese Ansicht präsentiert:

Unsere Kopie ähnelt dem Original, es gibt aber deutliche optische Unterschiede. Diese lassen sich bei einem Blick in den Quelltext schnell erklären. So finden wir an dessen Beginn folgende Zeilen:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title>bibliotheca Augustana</title>
<link rel="StyleSheet" type="text/css" href="../../../../css/f_germanica.css" />
<link rel="StyleSheet" type="text/css" href="../../../../css/f_canus.css" />
<link rel="StyleSheet" type="text/css" href="../../../../css/f_albus.css" />
<link rel="StyleSheet" type="text/css" href="../../../../css/f_viridis.css" />
<link rel="StyleSheet" type="text/css" href="../../../../css/f_ruberi.css" />
<script type="text/javascript" src="/145306DD-13EB-B04E-A47E-4375CD4BFE49/main.js" charset="UTF-8"></script></head>
In den <link>-tags werden Stylesheets angegeben, die die Wiedergabe der HTML-Elemente formatieren, insbesondere finden sich dort Angaben zur Schriftgröße und den verwendeten Farben. Wir können uns diese Stylesheets als Teil des Quellcodes von unserem Browser anzeigen lassen. In Firefox finden wir sie im Style-Editor:
In Microsofts Browser Edge benutzen wir die Navigationsansicht, um die Stylesheets zu finden und zu öffnen:

Die Navigationsansicht zeigt uns auch, wo der Browser diese Stylesheets findet: Auf demselben Server, wie die HTML-Datei. Er kann das genaue Verzeichnis dort relativ zum Speicherort dieser Datei identifizieren. Zwei aufeinanderfolgende Punke (..) bedeuten, das ein übergeordnetes „Eltern“verzeichnis gemeint ist. Von der HTML-Datei ausgehend, muss also zuerst das Urururelternverzeichnis (../../../../) gefunden werden, von diesem dann das „Kind“verzeichniss /css, in dem die Stylesheets gespeichert sind. Unsere Kopie allerdings ist auf unserem Privatcomputer gespeichert und damit funktioniert diese Art der Pfadangabe für sie nicht. Da uns rein optische Phänomene derzeit nicht interessieren, verzichten wir darauf, die Pfadangaben so anzupassen, dass unsere Datei auch äußerlich dem Vorbild entspricht.
Einen weiteren, tatsächlichen, Unterschied der beiden Dateien können wir hingegen nicht optisch in der Wiedergabe der Dateien im Browser erkennen. Suchen wir jedoch im Quelltext unserer Kopie nach dem Vers 5.11, dann werden wir dort nicht die ominöse Buchstabenfolge î finden, sondern direkt die entsprechende Graphie î. Für diese kleine Änderung hat in unserem Programm der Befehl html.unescape() gesorgt. Dieser Befehl setzt HTML-Kodierungen zur Wiedergabe von Sonderzeichen in entsprechende Buchstaben um.
Während es früher schwierig war, zu garantieren, dass Zeichen, die nicht im lateinischen Alphabet enthalten sind (genauer: im ASCII-Zeichensatz) überall richtig angezeigt werden, gehört dieses Problem inzwischen in vielen Bereichen weitgehend der Vergangenheit an. Der Blick in unser Browserfenster lehrt uns jedenfalls, dass moderne Browser keine Probleme mehr damit haben, die meisten Buchstaben korrekt wiederzugeben, ohne dass sie auf besondere Weise kodiert werden müssen.
Die Computersprache Python, besteht in ihrem Kern nur aus wenigen Vokabeln. Eine Vielzahl von Bibliotheken erweitern diesen Kern durch viele nützliche Befehle und Techniken. So praktische Helferlein wie das von uns eingesetzte Kommando unescape sind in Bibliotheken enthalten, die zum „Standardlieferumfang“ von Python gehören und können jederzeit durch Import aufgerufen werden, um die darin enthaltenen Techniken für unsere Zwecke einzusetzen. Den Befehl urlopen haben wir, wie leicht erkenntlich, der Bibliothek urlib.request entnommen. Wir beschränken uns in diesem Tutorial vorerst auf solche Bibliotheken die zum Python-Standard gehören und damit gut dokumentiert und leicht zugänglich sind. Für speziellere Aufgaben lohnt es sich, das Internet und insbesondere die Seiten der python.org nach maßgeschneiderten und optimierten Lösungen zu durchsuchen, die dabei helfen, das Rad kein zweites oder drittes Mal erfinden zu müssen. Wir werden später eine sehr populäre, nicht im Standard enthaltene (aber quasi zum Standard gewordene), Bibliothek verwenden, nachdem wir unser Ziel etwas weniger elegant mit „Bord“mitteln erreicht haben.
Jetzt aber versuchen wir zuerst einmal, unsere bisherige Methode auf die Website der Schweizer Parzival-Edition anwenden. Wenn wir allerdings diesmal die URL http://www.parzival.unibe.ch/cod857/Daten/NL_Transkripte/d_i_frm.html aus der Kopfzeile des Browsers übernehmen, werden wir nicht das erwartete Ergebnis auf unseren Rechner laden, bzw. im Konsolenfenster der Python-Umgebung angezeigt bekommen. Ausgegeben wird uns vielmehr ein Layoutgerüst, das festlegt, in welchem <iframe> die Bilddatei und in welchem die Transkription angezeigt werden soll.
Wir wissen ja, dass links der Transkriptionstext und rechts die Abbildung der Handschrift angezeigt wird. Es ist also keine Hexenkunst, herauszufinden, dass die von uns gesuchte Datei „d_i.html“ heißt und sich im selben Verzeichnis des Servers befindet, in dem das Layoutgerüst untergebracht ist:
<html> <head> <title>Transkription Parzival, Verse 1.01-58.26 (Buch I)</title> <frameset COLS="30%, 70%"> <frame name="links" src="d_i.html" scrolling="yes"> <frame name="rechts" src="" scrolling="yes"> </frameset><noframes></noframes> <script type="text/javascript" src="/145306DD-13EB-B04E-A47E-4375CD4BFE49/main.js" charset="UTF-8"></script></head> <body> </body> </html>
Wenn wir die URL also entsprechend anpassen (und den Namen der Datei, in die wir unsere Kopie speichern), wird uns die von uns gewünschte HTML-Datei von diesem Skript auf unseren Rechner geladen:
import urllib.request
import html
FileName = "http://www.parzival.unibe.ch/cod857/Daten/NL_Transkripte/d_i.html"
fInput= urllib.request.urlopen(FileName)
fOutput = open("D:/ParzivalBasel.html",mode='w',encoding='UTF-8')
for l in fInput:
print(html.unescape(l.decode('utf-8')))
fOutput.write(html.unescape(l.decode('utf-8')))
fOutput.close()
Diese Datei, die wir gerade erzeugt haben, sehen wir uns jetzt ein wenig genauer an (Im Folgenden wird nur ein verkürzter Ausschnitt zu Beginn der Datei angezeigt):
<html>
<head>
<title>Transkription Parzival</title>
<meta charset="UTF-8"/>
...
<link rel="stylesheet" type="text/css" href="NL_Transkript.css">
...
<head>
<h2>Buch I</h2>
<div class="schreiber">- Schreiber I -</div>
<div class="vers"><span class="versnr">1.01-0</span> <span class="marg">Der Parcival.</span></div>
<div class="vers"><span class="versnr">1.01</span> <span class ="si1"></span>ST zwiuel h(er)zen nahgebur</div>
<div class="vers"&gt;&lt;span class="versnr"&gt;1.02&lt;/span&gt; daz muͦz der sele werden sur&lt;/div&gt;
Auch diesmal kommt ein Stylesheet zum Einsatz, das das Aussehen der Ausgabe steuert und von uns ignoriert wird. Wir ignorieren momentan auch verschiedene weitere HTML-Elemente, beispielsweise Überschriften, die den Text gliedern, und versuchen nur diejenigen zu identifizieren, die den eigentlichen Transkriptionstext enthalten. Diese, so stellen wir fest, sehen dann so aus:
<div class="vers"><span class="versnr">.01</span> <span class ="si1">I</span>ST zwiuel h(er)zen nahgebur</div>
oder so:
<div class="vers"><span class="versnr">1.11</span> hat di swarzen <span class="k">va*</span> <span class="ls5">varwe&lt;/span&gt; gár.</div>
Der Transkriptionstext befindet sich also stets zwischen <div>-tags. <div>-tags kommen allerdings auch zu anderen Zwecken zum Einsatz. So wird uns auch die Information in <div>-tags präsentiert, dass dieser Teil der Handschrift von einem Schreiber geschrieben wurde, dem die originelle Bezeichnung Schreiber I zugeordnet wurde. <div> ist in HTML5 ein Allzweck-Element für Textabschnitte, das gerne benutzt wird, besondere Elemente zu bezeichnen, die durch die üblichen HTML-tags nicht adäquat erfasst werden können Genauer differenziert werden diese dann durch die Zuweisung einer Klasse. Elemente der Transkription befinden sich also, wenn wir es exakter erfassen, zwischen <div>-tags, die der Klasse „vers“ angehören und lassen sich somit problemlos von denen unterscheiden, die zur Klasse „schreiber“ gehören. Auf jedes Verszeile lässt sich durch eine ihr zugeordnete Versnummer verweisen und diese, so stellen wir fest, wird uns auch in jedem Vers angegeben, innerhalb eines <span>-Elements der Klasse „versnr“. <span>-tags rahmen keine Textabschnitte ein, sondern Teile eines Textabschnittes. Um sie herum gibt es Text oder kann es Text geben, während nach und vor einem Textabschnitt üblicherweise eine neue Zeile beginnt. Die Versnummern werden also korrekt innerhalb des Verses erfasst.
Zwei weitere Klassen die für <span>-tags möglich sind, können wir ebenfalls, spätestens beim Blick in die Handschrift, recht leicht interpretieren: In V. 1.11. hat der Schreiber (Schreiber I !) ein Wort (va) nicht ausgeschrieben. Abgekürzt hat er so wohl (das kann man schließlich aus anderen Handschriften erschließen), das Wort varwe. Die Klasse „k“ bezeichnet also ein in der Edition korrigiertes Element, die Klasse „ls5“ die von Editoren angesetzte „Lesung“ dieser Stelle. Tatsächlich ist es selbstverständlich ein wenig komplizierter, als wir es hier beschreiben, doch für unsere Zwecke reicht diese Zuordnung, die dem optisch erschließbaren Befund im Browserfenster bei Verwendung des zugeordneten Stylesheets entspricht. Hier werden die tatsächlich in der Handschrift anzutreffenden „Verschreibungen“ ausgegraut, die Korrekuren in einem hellen Blau wiedergegeben.
Die differenzierten Informationen, die uns diese Ansicht gibt und die noch differenzierteren Angaben, die wir dem Quelltext entnehmen können, macht deutlich, dass wir eine moderne, digitale Edition vor uns haben, die uns im Internet als HTML-Datei präsentiert wird. Dass der HTML-Datei wiederum eine für uns nicht zugängliche Fassung im strengeren und informativen TEI-Auszeichnungsschema zugrunde liegt, wird schon alleine durch die Verwendung der Klassenbezeichnungen und der Struktur der HTML-Datei deutlich.
So differenzierte Informationen erhalten wir durch den Quelltext der Website der bibliotheca augustana nicht. Hier handelt es sich nicht um eine digitale sondern um eine digitalisierte Edition. Es ist also nur eine für den Druck erarbeitete Edition die nachträglich in eine HTML-Fassung überführt wurde, die allenfalls einige typographische Signale der Druckedition übernimmt oder nachahmt. Außerdem ist es eine recht alte Datei. alt ist dabei natürlich in den Zeiteinheiten des Internets zu verstehen und ganz sicher nicht in denen der Mediävistik. In grauer Vorzeit diente HTML der Wiedergabe von Inhalten und zugleich der optischen Aufbereitung derselben. Und auch, wenn es auf den ersten Blick so scheinen mag, als habe sich daran nicht viel geändert: Spätestens seit der Einführung von HTML5 soll HTML ausschließlich als Beschreibungssprache der Struktur verstanden werden.
Die Bearbeiter der Editionen für die biblitheca augustana verwendeten, wie wir sahen, beispielsweise <h3>-tags zur Auszeichnung des eigentlichen Textes. Mit <h3> soll jedoch eigentlich eine Überschrift dritter Ordnung erfasst werden. Üblicherweise werden Überschriften der dritten Ordnung von den Browsern bis heute (wenn kein Stylesheet vorliegt) etwas kleiner und unauffälliger als solche der zweiten und erst recht der ersten Ordnung dargestellt, auf jeden Fall aber ein wenig prominenter, größer und möglicherweise dicker als einfacher „Normaltext“. Ganz eindeutig wurde <h3> also alleine aus typographischen Gründen für die Textauszeichnung gewählt, so wie Versnummern in <h6>-tags erfasst wurden. Zusätzlich zu den im Kopf der Datei angeforderten Stylesheets werden in den Verszeilen weitere „style“-Angaben gemacht, um etwa die Einrückung vom rechten Rand anzugeben.
Wir können allenfalls versuchen, strukturelle Informationen und vielleicht editorische Eingriffe aus den so notierten Angaben indirekt zu erschließen. Verlassen können wir uns auf diese Schlüsse nicht und werden deshalb vorerst nur versuchen, aus beiden HTML-Dateien den reinen Text ohne alle weiteren Elemente und zusätzlich erreichbaren Informationen zu entnehmen.
Doch werden wir damit erst im zweiten Teil dieses Tutorials beginnen.